Demyst Platform features
Understand the major features of the Demyst Platform
Components and features of the Demyst Platform
The Demyst Platform includes a variety of features for each of the core components, all helping you with the different aspects of managing external data at scale. A select set is diagramed below, with a complete set and relevant benefits tabled after.
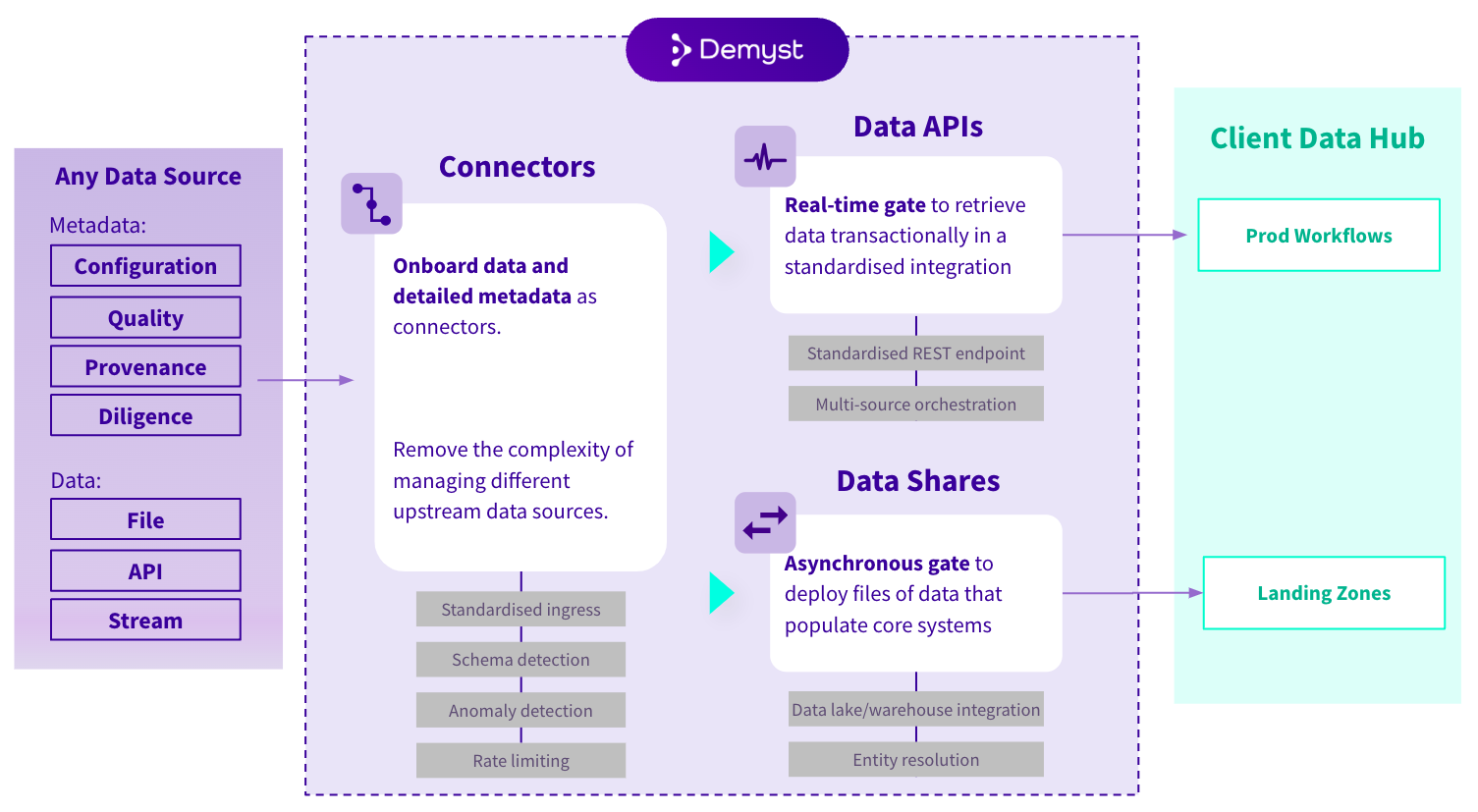
A select set of features of the Demyst Platform
Component | Feature names |
|---|---|
| Connector | Standardised ingress |
| Data API | Standardised REST endpoint |
| Data Share | Data lake and warehouse integration |
Organisation Management | Organisation configuration |
Feature details
Jump to Connector features and benefits
Jump to Data API features and benefits
Jump to Data Share features and benefits
Connector features and benefits
Feature Name | Description | Benefit |
|---|---|---|
Standardised ingress | Demyst's Connectors are created using a standardised ingress feature, automatically building the upstream data integration when supplied with the correct configuration information. This then triggers future stages of the Connector process like the schema detection, and connector metadata creation. | - Automation of this means data teams can optimise their time and resources by focusing on data analysis and insights |
Automated schema detection | Demyst's Connectors use automated attribute type detection when ingesting data from upstream sources. The feature works by analysing the input data to identify attributes and their types based on data patterns, structures and nomenclature. This is a form of automated metadata creation that is leveraged by other Demyst Platform components and downstream customer systems like catalogs. | - Simplifies data ingestion and preparation by eliminating manual identification and reduces the probability of data processing errors |
Anomaly detection | Demyst detects and flag anomalies when creating a Connector from bulk data by implementing custom data quality rules that are run during the data ingestion process. Anomalies include missing data, dictionary mismatch and others. This then triggers retry and remediation efforts with upstream data providers. | - Improves data quality and reduces likelihood of errors |
Rate limiting | Define rate limits applied to upstream data sources to meet contracted data provider requirements about limitations on rates of calling their APIs. | - Ensures compliance with data provider agreements while also preventing system overload and ensuring optimal performance by controlling the flow of data requests and API calls |
Connector performance and quality statistics | Demyst delivers connector performance and quality metrics through its metadata payloads. By analysing data such as latency, throughput, error rates, and other key performance indicators, you can gain insights into the health of your connectors and optimise their performance. | - Allowing data teams to identify and address issues in data ingestion and processing |
Automated catalog population | Populate and maintain data catalogs with standardised metadata payloads via a catalog metadata endpoint. Delivers in an agreed format so that all necessary fields in your data catalog can be programatically filled. These are provided on an agreed regular cadence to reduce effort of catalog metadata maintenance. | - Allows for improved data discovery |
Data movement logging | Enables detailed logging data movements throughout the system that then fuels Demyst's and your own monitoring, alerting and auditing efforts. Includes information like date of transaction/file transfer, IDs, who or what system is making a transaction or transfer data, success or failure information, errors, and more. This feature can allow for efficient billing and cost tracking by providing detailed records of data usage and movement, and also supports debugging and troubleshooting efforts by providing granular information about data transactions and their outcomes. Demyst delivers these logs through relevant API based payloads. | - Invaluable for tracking data usage, identifying potential issues, and ensuring compliance with regulations and best practices |
Error management | Demyst utilises a standardised error layer for data accessed through its product to simplify error management. This abstracts back from the downstream data source errors which typically vary, slowing down the integration development cycle by needing to deal with all new error types, and slowing response time to incidents. The Demyst Platform also offers simulation of error conditions. | - Effortlessly streamline your development cycle |
Monitoring and alerting | Demyst's monitoring functionality forms the foundation for timely responses to upstream data source incidents, and also helps with performance optimisation of deployed solutions. Customisation of alert rules (such as errors, latency and volume thresholds) enable automated issue detection across all deployed data sources, quickly identifying and notifying users of potential issues via web hooks. Both monitoring and alerting leverage Demyst's logging and error management features. | - Helps maintain the reliability and accuracy of data-driven applications |
Data lineage and provenance | Demyst delivers metadata payloads that support data lineage and provenance efforts, allowing you to document and track the entire journey of data from its origin to its final destination. These payloads include metadata about data sources, recency and other update dates, transformations applied, and any other changes made to the data over time. | - Providing improved data traceability and governance |
Automatic documentation generation | Demyst enables the programatic creation of standardised documentation for your technology team to leverage during all integration efforts, for both Data API and Data Share deployments. | - Reduces effort of integration as all documentation is in a standardised format that is easily accessible |
Data API features and benefits
Feature Name | Description | Benefit |
|---|---|---|
Standardised REST endpoint | Demyst's Data API all use a standardised REST endpoint, simplifying integration with production workflows by providing a uniform interface for data access. REST endpoints are supported by a wide range of programming languages and platforms. | - Simplifies integration with production workflows while providing flexibility and scalability |
Data API composition | Demyst enables the assembling of multiple upstream external into a single functional Data API with standardised input and output schemas. These APIs are quickly configurable by Demyst through our proprietary configuration language. | - This reduces the time and resources required to deploy Data APIs and enables more effective management of external data by enabling for changes in data providers without requiring code changes in the use cases consuming the data |
Data API orchestration | Demyst enables orchestration of multiple upstream external data sources through advanced logic such as water-falling (using one data source seamlessly as an input to another), failovers (logic to use one source only when another is unavailable), and other switching mechanisms (for example conditional logic based off field values on when to use one source over another). The output is a single API that leverage multiple upstream sources, orchestrated through logic. These APIs are quickly configurable by Demyst through our proprietary configuration language. | - These features allow to optimise for availability, costs or performance of a solution through using particular logic |
Data API schema customisation | Demyst enables simple configuration of output data structures for Data APIs. This feature enables users to customise the output format to meet specific requirements such as ensuring compatibility with various tools and systems. Output schema is customised in such a way that even if changes are made upstream by a data source, there is no need to make any changes in consuming systems. This feature also enables the creation of new attributes of data by applying logic on top of combinations of other attributes. Data APIs are quickly configurable by Demyst through our proprietary configuration language. | - Reducing the time required for data analysts to handle and process the data as the output is standardised to their needs |
Configurable transactional cache | Transactional cache configuration allows storage and retrieval of cached API data. The cache expiry is configured at the organisation level and enabled at the API level. | - Organisations can enhance performance and scalability, while simultaneously mitigating costs by reducing data source loads and response times |
Security management | With comprehensive security management options, you can implement various security measures such as role-based access control, IP whitelisting, and API key management to ensure that only authorised users and applications can access your data and Data APIs. | - This helps protect your sensitive information and prevent unauthorised access, ensuring the confidentiality, integrity, and availability of your data. |
API versioning | Demyst enables version control of your Data API. This feature allows you to track changes to the configuration of your Data API, providing an audit trail for data changes that can be more easily tracked and verified against. | - Simplify the process of data maintenance and ensure proper data lineage and provenance |
Test environment | The Demyst test environment means UAT versions of all Data APIs are available, providing data teams with the capability to validate hypotheses, conduct rapid iterations, and examine novel data sources prior to integrating them into production workflows, and for further iteration after integration without affecting production flows. | - This enables teams to effortlessly test and evaluate data fit for specific use cases, enabling them to detect and correct issues early in the development cycle, resulting in time savings and a decreased risk of errors during production |
Realtime data harmonisation | By leveraging Demyst's other Data API configuration features in unison, you can harmonise data across multiple external data sources in realtime. This means the creation a single API that generates a single golden record that internal customers can use, that harmonises across multiple upstream sources. It leverages the logic you create and hides the complexity of harmonising across multiple sources from your internal customers. This feature reduces maintenance effort by allowing seamless swapping of data sources without a change in the output schema, removing the need for manual intervention in your own code or pipelines to do so. | - Reduces maintenance time by reducing manual intervention |
Realtime data replication in warehouse | This feature enables organisations to capture data from transactions made against Data API, and then populate the right data warehouse or lake with those records as well. This supports organisations in ensuring compliance with regulations about data retention, while also making data easily accessible for analysis across the organisation. It also allows teams to quickly and easily access only the specific attributes they need for their realtime workflows, while still keeping the full record available for analytics and reporting purposes. | - Organisations can support regulatory compliance initiatives while also making data easily accessible for analysis across the organisation |
Data Share features and benefits
Feature Name | Description | Benefit |
|---|---|---|
Data lake and warehouse integration | Demyst's Data Share payloads deliver data into a standard landing zone for your organisation to pull from. They are compatible with major cloud platforms, supporting both push and pull, scheduling, automatic quality checks, and more. | - Simplifies the complex task of managing large volumes of data from disparate sources |
Data share configuration | Demyst enables simple configuration of Data Share payloads of data, applying the necessary ETL jobs to transform upstream data from any source into the "agreed in advance" standardised format, naming conventions, encryption, encoding, keys, record validation method, retry mechanism, delta file settings, and more. | - Reducing the time it takes to ingest and manipulate data into a workable data product as payload and ingestion method is always standardised and uniform, with a lot of preliminary ETL already done |
Data Share scheduling | Ensure that your Data Shares, such as recurring enrichments of data, are being delivered on an agreed schedule, with appropriate settings for retry mechanisms and other forms of error handling. | - Reduce your maintenance cost of data delivery through automation, with scheduling and associated error and handling and alerting for it |
Entity resolution | Demyst enables users to match their internal data to specific external data sources, for data enrichment purposes, adding extra column of data against supplied input data lists. The entity resolution technology utilises data schema analysis across common identifier types (such as business name), and a variety of matching rules. | - Reducing errors and improving match rates, resulting in higher quality data |
Data Share versioning | Data Share versioning provides a clear way to track changes to the structure of the data payload over time. With versioning, data teams can ensure that consumers are using the correct payload format. This also enables teams to make changes to the payload structure without disrupting existing data consumers, as they can continue using the previous version until they are ready to update to the new version. | - Better data consistency and management |
Other features
Component | Feature Name | Description | Benefit |
|---|---|---|---|
Organisation Management | Organisation configuration | The Demyst Platform supports configuration of all organisation settings so that all information security and process requirements can be met. This includes SSO, MFA, user access controls, IP whitelists, and other enterprise grade security functionality. | - Meet all your information security requirements by configuring the right settings for your organisation based off internal policies |
Updated 6 months ago